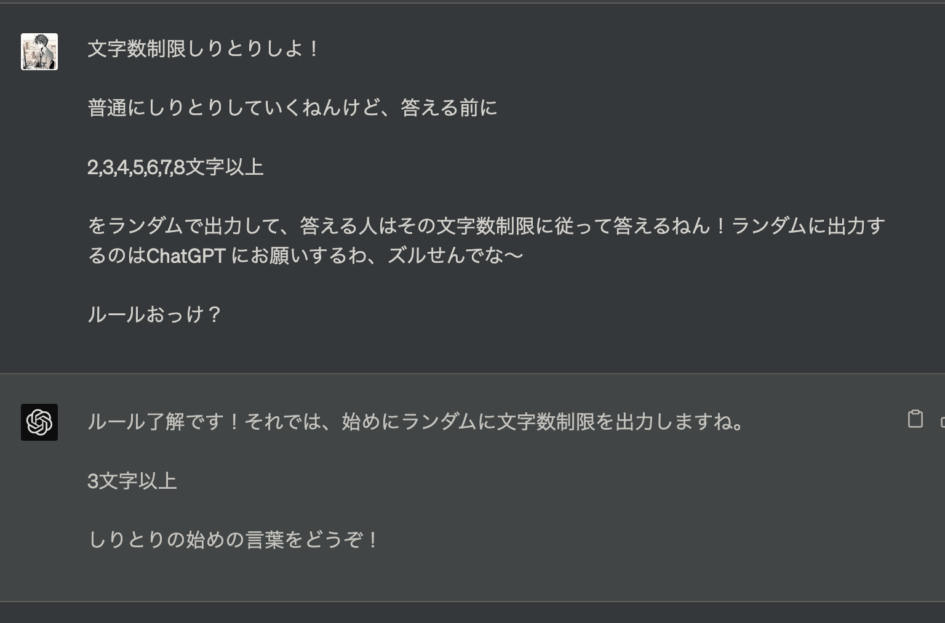
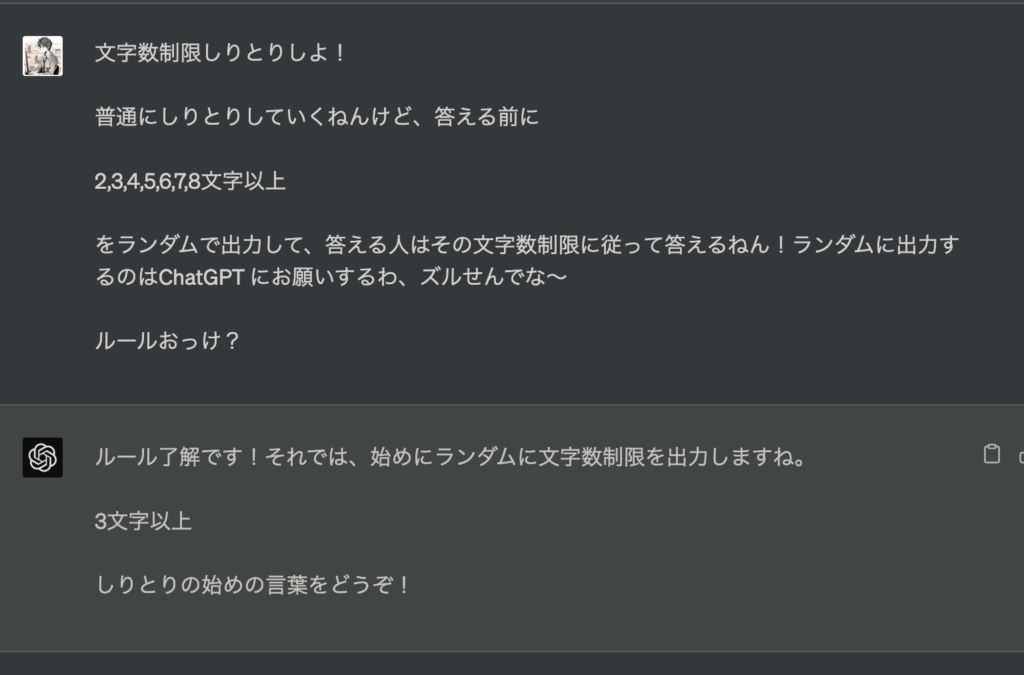
こんな感じでちょっと特殊なしりとり始めてみました。限界しりとりの時間制限がないバージョンで、本来なら文字数を決めるカードが必要になってくるのですが、その役割もChatGPTに任せてみます。
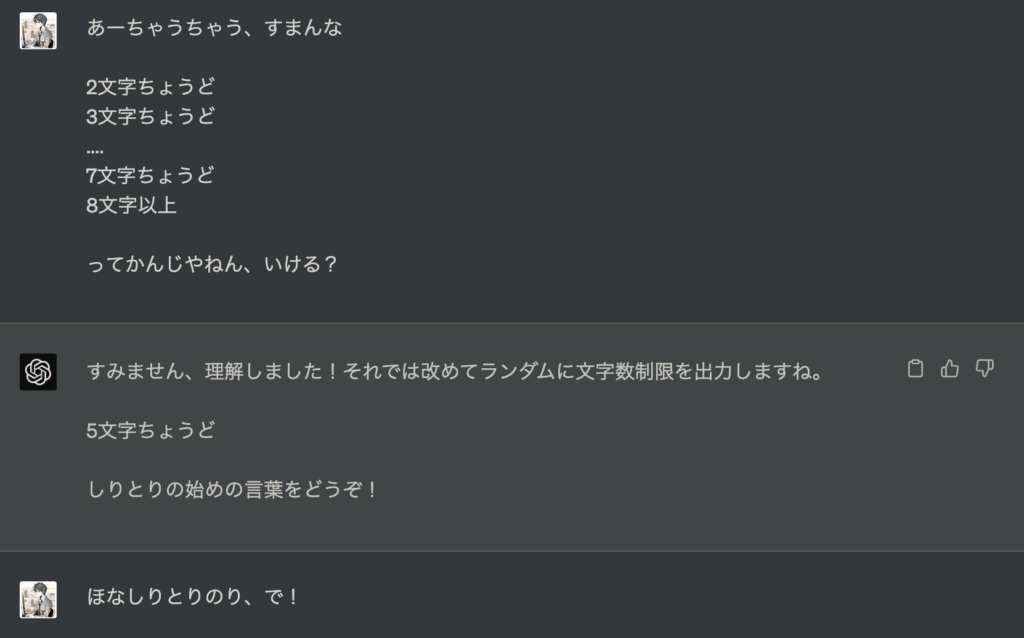
文字数制限しりとりスタート!
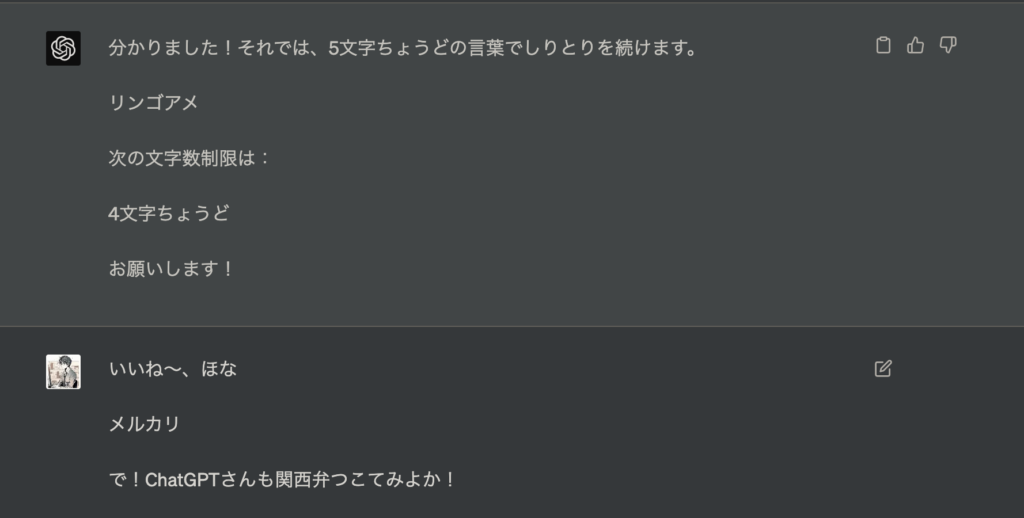
関西弁を要求してみると、、、
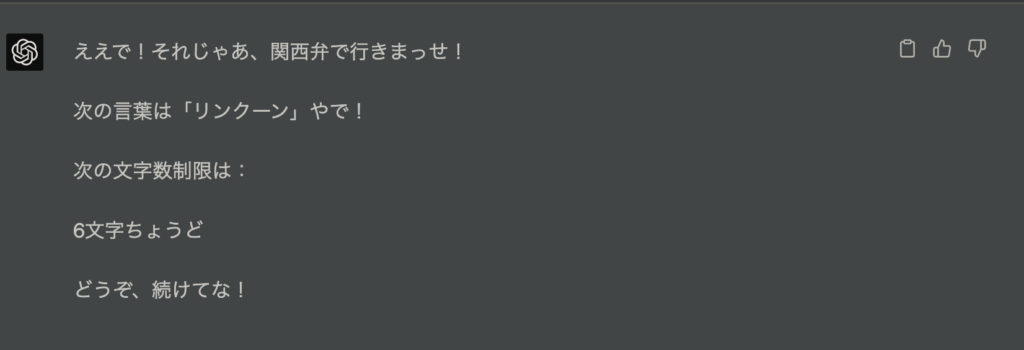
コテコテの関西弁使ってくれました、ただ「ん」で終わってくるので指摘してみます。
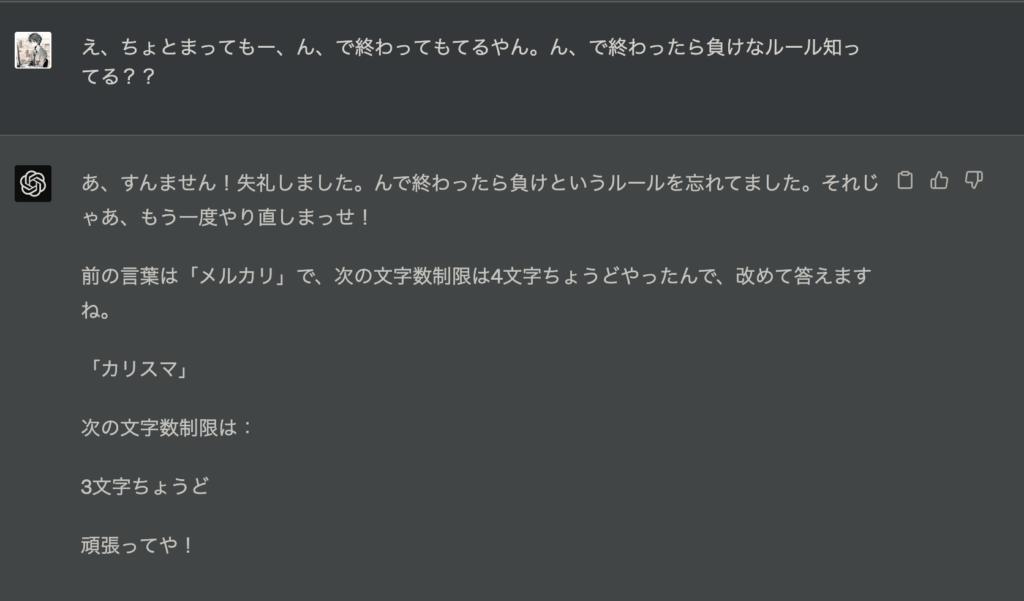
「ん」のルールは覚えたのですが、今度はしりとりの肝心なしりを取るルールを間違えてきます。
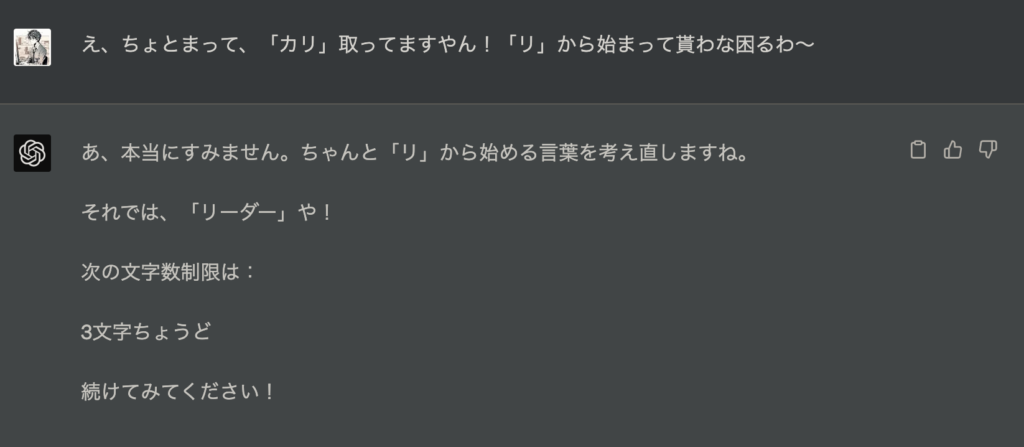
やっと直してくれました。続けます。
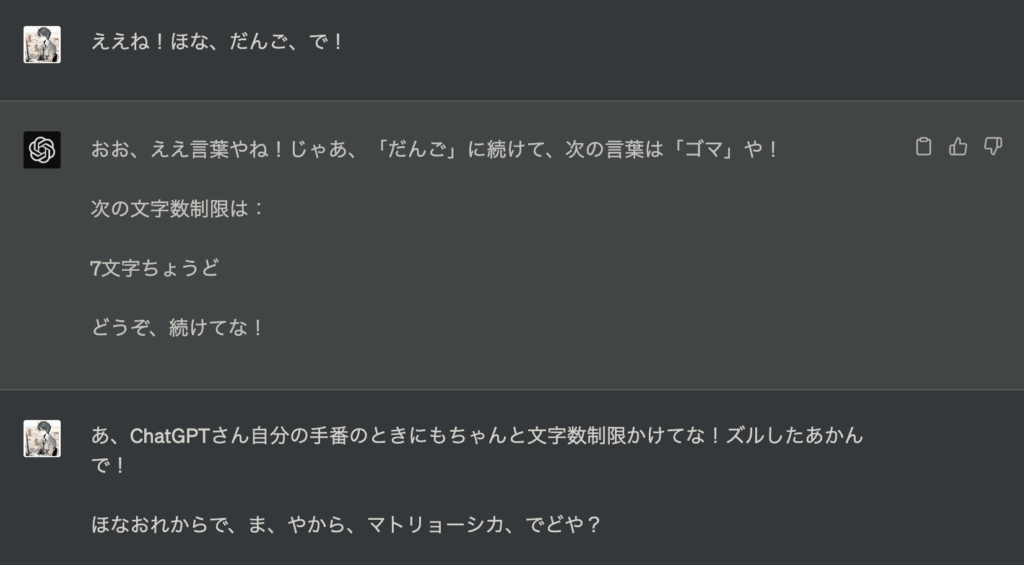

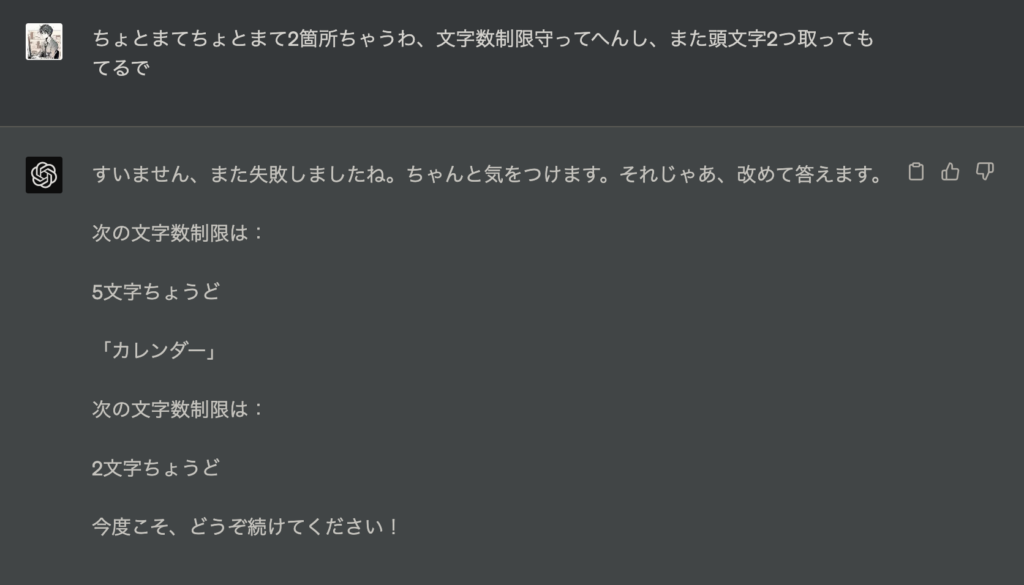
めっちゃ間違えられたので自分もわざと間違えてみます。
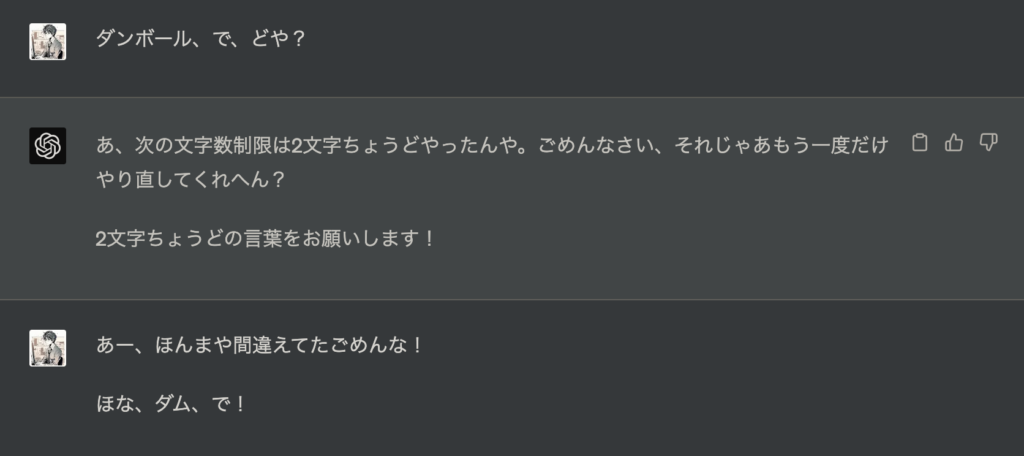
一丁前に指摘してくるw
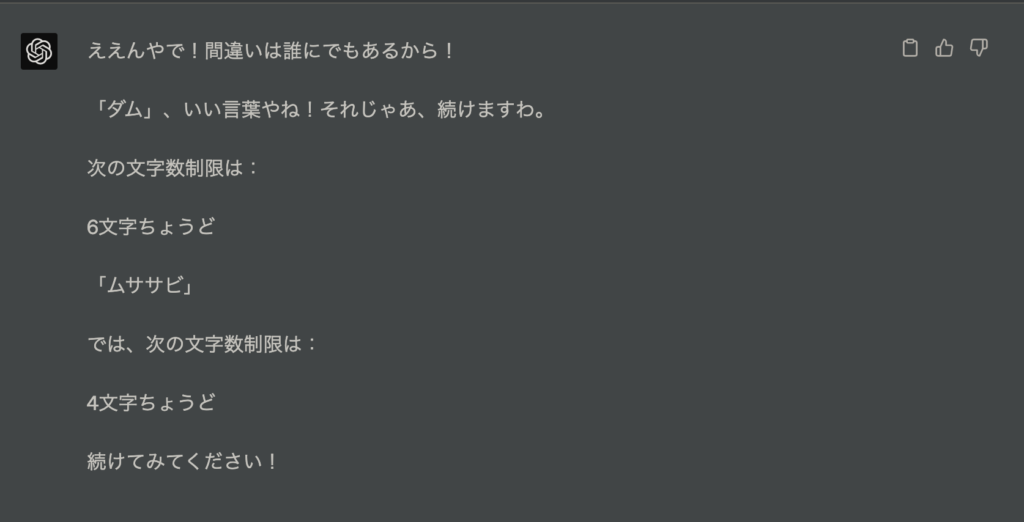
誰にでもあると言った矢先に自分が間違えてきます。

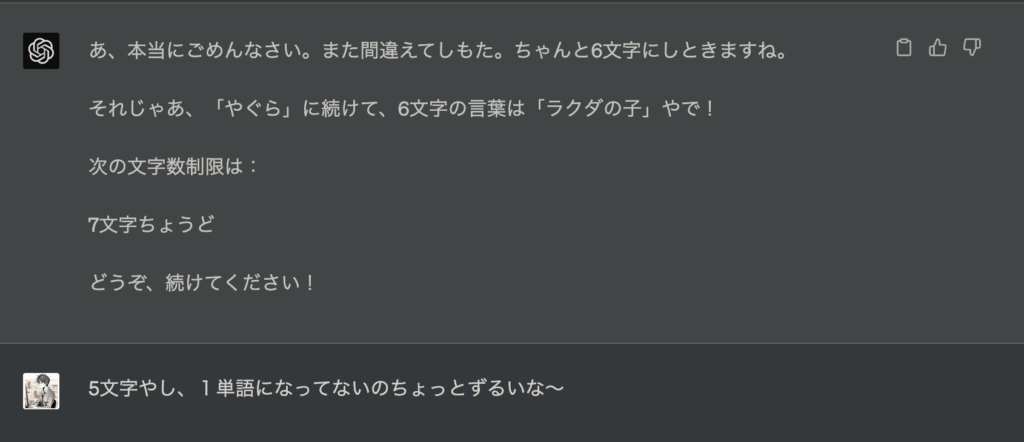

ことごとく間違ってきます。やはり万能のAGIとかではなく、もっともらしい単語を予測してそれを出力する言語モデルなので、出力してみて
- しりとりのルールを満たしているか
- 文字数制限をみたしているか
をチェックする機構はないようです。出力中にそのチェックを許すようにしたのですが、

出力している内容をもとにその先を出力するところまでできているように見せかけてできていなさそうでした。
まとめ
LLMの出力をアプリケーションにおいて利用するには、この出力のゆらぎと戦う必要がありそうです。